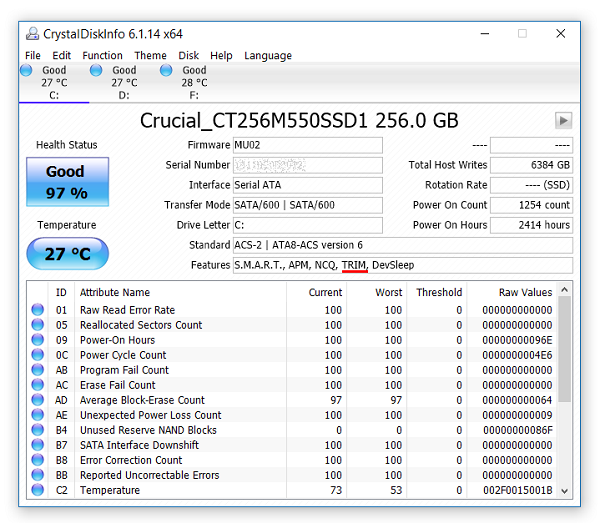
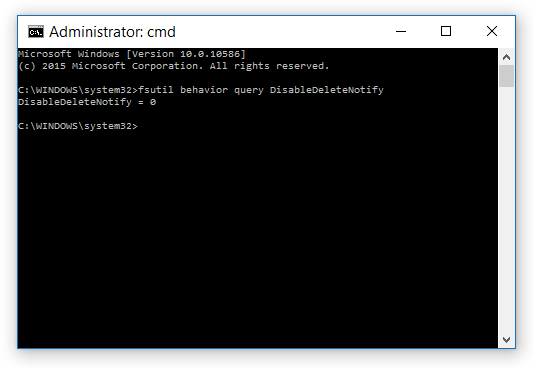
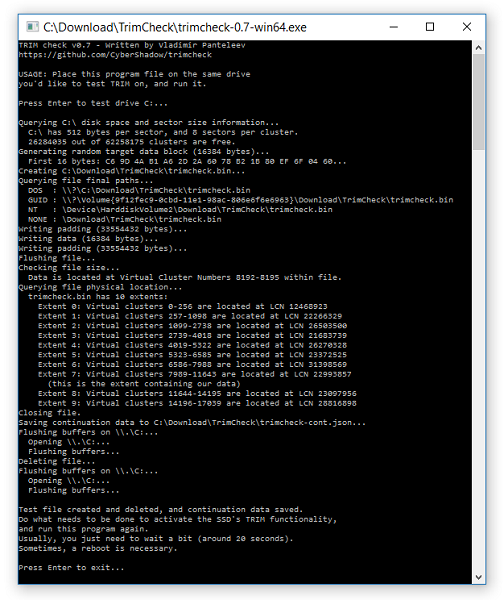
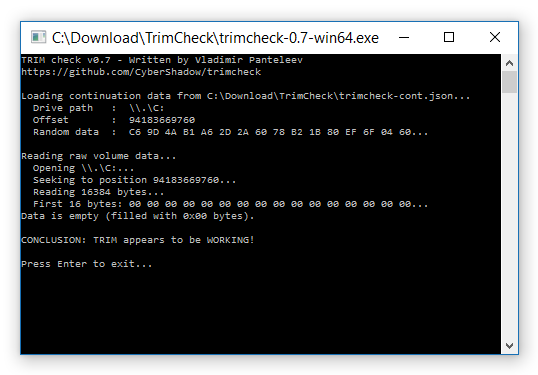
by Nadeem Alherbawi*, Zarina Shukur & Rossilawati Sulaiman; Faculty of Information Science and Technology, Universiti Kebangsaan Malaysia
Abstract
Data carving is a very important topic in digital investigation and computer forensics. And for that reason research is needed to focus on improving data carving techniques to enable digital investigators to retrieve important data and evidence from damaged or corrupted data resources. This paper is the result of a systematic literature review which answers three main questions in data carving filed. The Results fall into four main directions. First it shows the need of realistic data sets for tools testing. Secondly, it points to the need of object validation under fragmented data storage. Thirdly, investigating content based validation and its benefits in digital investigation field. Finally, it points to a new direction in data carving such as in-place data carving, bulk extractor and using semantic validation in data carving. Finally, a set of potential areas of interest are pointed out that needs further research and investigation.
Introduction
Digital or computer forensics is defined as the practice of identifying, preserving, extracting, analyzing and presenting legally sound evidence from digital media such as computer hard drives [1]. Since the past ten years digital forensics has changed from a technique which was almost solely used in law enforcement to an invaluable tool for detecting and solving corporate fraud. As digital forensics plays a vital role in solving digital crimes it is worth being investigated. The following section describes this role of file recovery in a forensic setting.
During a digital forensic investigation many different pieces of data are preserved for investigation, of which bit-copy images of hard drives are the most common way for the process [2]. These images contain the data allocated to files as well as the unallocated data. The unallocated data may still contain information relevant to an investigation in the form of intentionally deleted or automatically make a deletion of temporary files. Unfortunately, this data is not always easily accessible. However, a string search on the raw data might recover interesting text documents, but it would not help getting information present in, for example, images or compressed files. Beside, the exact strings to look for may not be known beforehand. Getting to this information, the deleted files have to be recovered.
There are multiple ways to recover files from the unallocated space. Most techniques use information from the file system to locate and recover deleted files. The advantage of this approach is that it’s relatively fast and the meta-information, such as last access date, can often be recovered as well [3]. The downside of this approach is that these techniques become much less effective if the file system information is corrupted or overwritten. In these cases, a new technique that works independently without need of the file system information is required. In other words, this can be done by identifying the deleted files and file parts directly in the raw data and extracting them in a verifiable manner [4].
Motivation
Carving is a general term for extracting files out of raw data, based on file format specific characteristics present in that data. Moreover, carving only uses the information in the raw data, not the file system information. Nicholas Mikus wrote “Disc carving is an essential aspect of Computer Forensics and is an area that has been somewhat neglected in the development of new forensic tools” [5]. In the two years since this thesis the field of carving has evolved considerably, but there are still many possible areas of improvement.
Most notably, there are a few different carving techniques and there is no standard method of rating or comparing between them. Also little scientific information on carving and the results of carving tools which needs to be improved. This means that this field provides multiple possibilities for projects that combine scientific research into fundamental carving issues with practical improvements of carving tools [6].
In 2006 the Digital Forensics Research Workshop (DFRWS) issued a challenge to digital forensic researchers worldwide to design and develop file carving algorithms that identify more files and reduce the number of false positives. Nine teams took up this challenge. The final results of this challenge, and its winners, caused some discussion on how a carving tool should be rated. The winning team used manual techniques to recover the deleted files, which, as Metz and Mora stated, does not scale for realistic data sizes [7]. Finally, most current carving tools focus on data recovery rather than evidence search, which results in many lost potential evidences that could be used in a court of law; for that reason a study of literature is needed to discover needs and gaps.
Systematic Literature Review
In order to review the current state of the art related to data carving in digital investigation point of view, a systematic literature review has been done following the procedures mentioned by [8]. The research questions that need to be raised are in the Table 1.
![]()
The search was done on several digital libraries and databases, the language in the searching process was English. The publishing date was not defined. Focus was only on the articles that are related to computer forensics, or digital investigation on disk area. All other irrelevant area articles were dropped.
Sources of digital libraries and databases that have been searched were IEEEXplore, Springer link, Scopus, Science Direct, ACM, and DFRWS (Digital Forensics Research Conference). Table 2 shows search strings used in above mentioned sources.
![]()
The initial search ran in October 2011. Table 3 presents all findings related to each source. The selection of study involves multiple phases. First potentially relevant studies were identified using search strings, then screening made on the title and abstract of the publications. As a result a large number of publications were excluded based on their irrelevance to the research questions. On the other hand, if there was any doubt about the inclusion of potential publications the full paper would be obtained for further assessment [8].
![]()
In terms of the quality of publications, a full text scanning has been made on the final set of the journals. Mendeley software has been used to manage all publications and citations. As a result a set of publications has been included in the review based on its relevancy to the research questions mentioned in table I and based on the clearance of their objectives and methodology.
3.1 Data extraction
Table 4 represents a sample of data extraction form that consist of five sections. Namely publication title, Methodology used by the author, questions answered by publication depending on table 1, and finally Tag which relates the content of Table 4 with Figure 1.
![]()
![]()
3.2 Analysis of the results
In this section an analysis of the results of the systematic literature review will be shown. Figure 1 represents a general illustration of the answers for the research questions mentioned previously in table 1. Consequently, an elaborative analysis will follow in the next paragraphs.
The techniques used in file carving answer one of the Research questions. Fragmentation is considered as a serious issue and because of that, techniques were developed to consider it. For contiguous data it is usually easy to be carved using header / footer techniques which use header of specific file type and its footer as a unique identification flag. After that all the data between the header and footer will be considered as a file data section. Most of the standard formats have their own unique headers and footers which will be used in the carving process to identify and recover data.
Additionally fragmented data has a different story. The previous technique will not work since the header and its respective footer maybe not be sequentially ordered, and accordingly another file footer may exist in between. As a result if the previous technique is being used then the carver will recover a bad corrupted file. In this way, a general approach called ‘file structure based carving’ has been introduced. For each type file or category of files a different technique is needed since the carver needs to check and use the structure inside the data blocks to decide if these blocks of data are consistent and consider as one coherent unit in a file [15].
![]()
To clarify, if we take JPEG file format, the carver uses the Huffman code table to identify file fragments by comparing the table results with the results of matching blocks, which may or may not have fragments of that file. Additionally, another file format has its different way of identifying file fragments and much research is done on this field considering many different file formats including zip files, PDF files, PNG, and XML based documents such as DOCX. For each one of these file formats a different technique will be used to recover them [1].
The above technique used to recover fragmented data still produces high false positive rates. Since the file structure of the file which is used to identify fragments may be missing, or altered, or corrupted, carvers produce a higher number of potential files which lead to double or triple the storage size of carved data [16].
The previous paragraphs form an introduction to the traditional form of data carving and its issues. On the other hand in the following sections a review of a new non traditional data carving techniques will be covered. The first section covers In-place carving. The second section covers forensic feature extraction and bulk extractor. The last section covers the topic of object validation in data carving and datasets.
A. In-place carving
In-place carving is one type of data carving which reduces the amount of recovered data which may get multiplied hundred times of the original media size. For example in one case carving of a wide range of file types from 8 GB target results in a total carved files which was over 250 GB of storage [17].
The issue of the current practice of file carving is recovering data into new files which holds a big performance cost that is inherent and cannot be solved by optimizing the file carving software. The only argument for this approach is that virtually all the carvers used to view or process the recovered data need a file based interface to the data. A new approach is needed that adds a file system interface to the output of the carver without actually creating carved files. Particularly if a file system interface is arranged to candidate files without physically recreating files, existing file carvers can still be used without creating new files, many of which will likely be invalid. This approach is called “in-place” file carving. The technique is similar to that used by current file systems, except that file system metadata is stored outside the target [17].
Figure 2 illustrates the differences between traditional and in-place carving. The host file system and forensic target can be thought of as “input” to both traditional and in-place carving. In traditional carving, both the metadata and the data for carved files are dumped into the host file system, and the target has no significant role after the carving operation completes. In the case of in-place carving, a database of metadata is inserted into the host file system, indicating where potentially interesting files are located in the target . In order to use the in-place technique and save time and space, a multi-level system is proposed. [17] Suggest an in-place carving architecture, the first part of the proposed architecture ScalpelFS. ScalpelFS comprises three main elements, the first one is Scalpel v1.60, which provides a new mode called preview, made of a custom FUSE file system that is the second element for the purpose of providing a standard file system view of carved files. The third element is the Linux network block device, for the purpose of carving of remote disk targets.
![]()
The Dutch National Police Agency has proposed another similar approach named as the carved path zero storage Library and filesystem (CarvFs). They develop a library that provides the low-level needs of zero storage carving. It does this by providing an interface to hierarchically ordered fragment lists, and allowing these fragment lists to be converted to and from virtual file paths. These particular virtual file paths can be used in conjunction with the CarvFS filesystem, a pseudo filesystem build using fuse and LibCarvPath [13].
Finally in-place carving helps a digital investigator to reduce the numbers of carved files which need to be analyzed and examined for evidence, which reduces the time needed by the investigator. Also in-place carver is in many cases faster than regular carvers. For instance 16 GB storage needs 30 minutes extra when a traditional carver Scalpel is used [18].
B. Forensic Feature Extraction And Bulk Extractor
Forensic investigators become the victims of their achievement. Since digital storage devices in all different shapes are such valuable sources of information, they are now routinely seized in many digital investigations. As a result, investigators do not have the time to investigate all the storage devices that comes across their desks. When the investigator is available, the contents of the device are copied to a working storage drive to maintain chain of custody. This bit to bit copy of the drive is then opened or mounted using a forensic tool, after that the investigator can perform variety of analyses such as string searches or manually exploring the image. When the analysis is finished, the copy is removed from the system, and the investigator handles the next drive.
The previously mentioned approach has multiple drawbacks as has been pointed out by [19]. First, it has priority issue related to which has to come first the resources and storages or the attention of the examiner on the value of information that the storage media contains. The second issue is related to the lost potential correlation among data from various storages, files, and objects, which can help in connecting all the dots related to the case on the hand. Finally, traditional forensic tools focus on recovering documents while the traditional approach neglects data on the drive that cannot be reconstructed to be filed. Forensic tools should be enhanced and adapted to be evidence focused rather than documents and files recovery.
Currently, two general techniques are common in the processing of digital evidence that balance each other: file-based approaches and bulk data analysis. The file-based technique is widely used by digital forensic investigators and many popular tools such as EnCase and AccessData’s FTK implement this approach. This kind of approach operates by finding, identifying, extracting and processing files pointed by file system metadata [10]. This has multiple advantages among other techniques since it’s easy to understand, and it integrates well with most legal systems since extracted files can be easily utilized as evidence. On the other hand, it suffers from ignoring data that are not contained within files or not pointed out by metadata entries [2].
On the other hand, bulk data analysis techniques examine data storage and identify potential evidence based on content, then process and extract without returning or using file system metadata. An example of this approach is file carving, but it has the limitation of ignoring bulk data that cannot be assembled into files. Both methods – file based and bulk data analysis – complement each other. In a file-based approach, the results are easier to put in context and to be explained to an individual who does not have technical knowledge. On the other hand, bulk data analysis applies on all kinds of computer systems, file systems and file types since it does not rely on the metadata of the file system. Additionally, it also can be applied on damaged or partially overwritten storage media.
Feature extraction technique is a new model for bulk analysis that works by first scanning and searching for pseudo-unique features which are an identifier that it has sufficient singularity such that within a giving data it is highly unlikely that the identifier will be repeated by chance, and then storing the results in an intermediate file. An example of both feature extraction and pseudo-unique features is and email extractor which can recognize RFC822-style email addresses via unique identifiers which are the Message-ID value [19].
The bulk extractor is an example of a tool that applies the two previously mentioned approaches above. The program operates on multiple disk images, file, or a directory and extracts useful information without returning to the file system metadata [10]. The results can be easily checked, determined, or processed with automated procedures. Bulk extractor also creates histograms of the occurrence of features that it finds since features that are more common in the media tend to be more important.
The bulk extractor has multiple scanners that run sequentially on target digital evidence, and each scanner record extracted features in a certain mechanism and then the tool performs post-processing for the extracted features and then exits. The bulk extractor has two types of scanner, basic and recursive. An example of a basic scanner is an email scanner that searches for email addresses, RFC822 headers, and other recognizable strings in the email message. A recursive scanner, as the name implies, can decode data and pass it back for re-analysis for further scanning. An example of this kind of scanner is zip-scanner, since a compressed file may contain multiple types of other data forms and files.
C. Object Validation In Data Carving and Datasets
Object validation in carving is also considered an issue. Garfinkel defined object validation as the process of determining which sequence of bytes represent a valid JPEG or PNG or any kind data. Object validation is a subset of file validation since some files may contain multiple objects and for that the carver may recover these objects separately [11].
Another important topic in object validation is using content validation, which we will focus on in our development of an enhanced in-place carver. In general, content validation tries to validate files based on content, such as using semantic validation that uses human languages in the process of validation. That kind of validation works well with document type files. Over and above content validation can be used as a part of in-place carving to identify specific files based on its content. This approach can be more beneficial in the digital investigation process. For instance, if the investigator wants to find out any evidence of any malicious act, he can use in-place carving with a focus on searching in the content part of files to scrutinize any kind of malicious code. If the carver found such a code it will carve that file. The last issue is to use aspects of languages such as English as validation indicators. Many authors suggest semantic validation for the results of carving tools to reduce false positive rates. More work needs to be done for the purpose of automating this approach and supporting many languages. [20]
Finally, testing the carving tools is another major issue. It deals with how to measure the tools’ performance, accuracy, and false positive / negative rate. In this matter Garfinkel points out the need for a realistic dataset, which can be used to test and validate files that have been recovered [2]. This will enable researchers to figure out weaknesses in the developed tools and increase their quality. The same author developed the most used corpus for testing carving tools, which was used by the DFRWS challenge in 2006. Developing a realistic dataset is not an easy goal since researchers need a huge number of disks and also permission from users who own these disks to be able to use them for research purposes [9].
Conclusion
Throughout the whole process illustrated above, four main areas have been defined. The first one is the need for a real dataset or corpus that will be used to better test the carving tools and the results. There are a few realistic datasets which can be used for testing purposes, but those current ones do not reflect real complexity and openness. To achieve this a framework for developing automated solution, a more realistic dataset is needed.
Secondly validation: this is necessary in fragmented files, especially in the domain of digital forensics. For example if we have a sequence of bytes, then the process of validation has to produce a valid file. To clarify, for JPEG file, the process validation will depend its internal structure, i.e., the entries of Huffman table. Since each file type has a different internal structure more research is needed to cover all kinds of data types, which needs its own way of validation.
Thirdly semantic validation, which uses languages in the process of validating files, is an urgent issue. For instance if we have a text file or a document the content of the file should contain valid words, furthermore the file can be known as invalid if the carved file has nonsense words that do not have meaning. Therefore that file is carved incorrectly. Using the above approach will reduce false positive rates. Accordingly, more investigation is needed regarding semantic validation. Another potential point is to investigate new ways for feature bulk analysis, which is essential for encoded data such as MP3 files and JPEG images, since current models and tools search for features from text based files such as docs and text files.
Finally enhancing the carving validation process to enable it to detect injected codes, hidden data or potential evidence is needed by digital investigators. Most of the validation process focuses on testing the file structure as an indicator of file validity but not concentrating on the content of the file itself. For example, if we have a picture recovered correctly by the carver, and within the data blocks of the picture malicious code were hidden, this kind of information is very important in the field of digital investigation. For that reason content based validation from a digital forensic point of view is essentially needed.
References
[1] D. Povar and V. K. Bhadran, “Forensic data carving,” in Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering, LNICST, 2011, vol. 53, pp. 137–148.
[2] S. L. Garfinkel, “Digital forensics research: The next 10 years,” Digit. Investig., vol. 7, pp. S64–S73, Aug. 2010.
[3] A. Pal and N. Memon, “The Evolution of File Carving,” IEEE Signal Process. Mag., no. March, pp. 59–71, 2008.
[4] C. J. Veenman, “Statistical disk cluster classification for file carving,” Proc. – IAS 2007 3rd Int. Symp. Inf. Assur. Secur., pp. 393–398, 2007.
[5] Nicholas Mikus, “AN ANALYSIS OF DISC CARVING TECHNIQUES,” 2005.
[6] L. Aronson and J. Van Den Bos, “Towards an Engineering Approach to File Carver Construction,” 2011 IEEE 35th Annu. Comput. Softw. Appl. Conf. Work., pp. 368–373, Jul. 2011.
[7] B. J. Metz, “Shrinking the gap : carving NTFS-compressed files,” October, no. October 2009, 2009.
[8] M. M. Yusof, “SOFTAM : Systematic Review Hands-on Workshop,” Rev. Lit. Arts Am., pp. 1–12, 2011.
[9] S. L. Garfinkel, “Forensic corpora: a challenge for forensic research,” Electron. Evid. Inf. Center, April, pp. 1–10, 2007.
[10] S. L. Garfinkel, “Digital media triage with bulk data analysis and bulk-extractor,” Comput. Secur., vol. 32, pp. 56–72, 2013.
[11] S. Garfinkel, “Carving contiguous and fragmented files with fast object validation,” Digit. Investig., vol. 4, pp. 2–12, Sep. 2007.
[12] R. D. Brown, “Reconstructing corrupt DEFLATEd files,” Digit. Investig., vol. 8, pp. S125–S131, Aug. 2011.
[13] X. Zha and S. Sahni, “Fast in-Place File Carving for Digital Forensics,” Forensics Telecommun. Information, Multimed., pp. 141–158, 2011.
[14] Y. Guo and J. Slay, “Chapter 21 DATA RECOVERY FUNCTION TESTING,” Ifip Int. Fed. Inf. Process., pp. 297–311, 2010.
[15] H. T. Sencar and N. Memon, “Identification and recovery of JPEG files with missing fragments,” Digit. Investig., vol. 6, pp. S88–S98, Sep. 2009.
[16] D. Park, S. Park, J. Lee, and S. No, “A File Carving Algorithm for Digital Forensics,” Order A J. Theory Ordered Sets Its Appl., pp. 615–626, 2009.
[17] G. R. Iii, V. Roussev, and L. Marziale, “Chapter 15 IN-PLACE FILE CARVING,” .
[18] L. Marziale, G. G, R. III, and V. Roussev, “Massive threading: Using GPUs to increase the performance of digital forensics tools,” Digit. Investig., 2007.
[19] S. L. Garfinkel, “Forensic feature extraction and cross-drive analysis,” Digit. Investig., vol. 3, no. SUPPL., pp. 71–81, 2006.
[20] R. Poisel and S. Tjoa, “Roadmap to approaches for carving of fragmented multimedia files,” in Proceedings of the 2011 6th International Conference on Availability, Reliability and Security, ARES 2011, 2011, pp. 752–757.
About the Authors
Nadeem Alherbawi is a PHD student at Universiti Kebangsaan Malaysia. He received his bachelor degree at Palestine Polytechnic University and his master at Universiti Teknologi Malaysia in computer science and specifically in information security field. His research area focuses on computer forensic and data carving, as well as information security in general.
Prof. Zarina Shukur is a Professor in the School of Computer Science at Universiti Kebangsaan Malaysia. She received her Bachelor degree at Universiti Kebangsaan Malaysia and PhD at University of Nottingham, and joined as faculty member at UKM since 1995. Her research area is in software testing and verification, as well as application of computing techniques.
Dr. Rossilawati Sulaiman is a Senior Lecturer in the School of Computer Science at the Universiti Kebangsaan Malaysia (UKM). She received her Bachelor degree at UKM. She did her MSc at the University of Essex and her PhD at the University of Canberra. She has been working with UKM since
2000. Her research area is in Cryptography and Multi-agent System.
You can find the full paper and citation references on Medwell Journals.
![]()
![]()
 This article is a recap of some of the main highlights from the Forensics Europe Expo which took place at Kensington Olympia Conference Centre, London, on the 19th-20th of April 2016.
This article is a recap of some of the main highlights from the Forensics Europe Expo which took place at Kensington Olympia Conference Centre, London, on the 19th-20th of April 2016.